## Thinking Path > - Paperclip is a control plane for autonomous AI companies where work must stay observable, governable, and recoverable. > - The task/heartbeat subsystem owns agent execution continuity, issue state transitions, and visible recovery behavior. > - Waiting on an external service is not the same as being blocked when the assignee still owns a future check. > - The gap was that agents had no first-class one-shot monitor state for external-service waits, so recovery could look stalled or require ad hoc comments. > - This pull request adds bounded issue monitors that can wake the owner, clear exhausted waits, and produce explicit recovery behavior. > - It also surfaces monitor status in the board UI and documents when to use monitors versus `blocked`. > - The benefit is clearer liveness semantics for asynchronous waits without weakening single-assignee task ownership. ## What Changed - Added issue monitor fields, shared types, validators, constants, and an idempotent `0075` migration for scheduled monitor state. - Added server-side monitor scheduling, dispatch, recovery bounds, activity logging, and external-ref redaction. - Added board/agent route coverage for monitor permissions and child monitor scheduling. - Added issue detail/property UI for monitor state, a monitor activity card, and Storybook stories for review surfaces. - Documented monitor semantics and recovery policy behavior in `doc/execution-semantics.md`. - Addressed Greptile review feedback by preserving monitor state in skipped-stage builders and making board monitor saves send `scheduledBy: "board"`. ## Verification - `pnpm install --frozen-lockfile` - `pnpm run preflight:workspace-links && pnpm exec vitest run server/src/__tests__/issue-execution-policy-routes.test.ts server/src/__tests__/issue-execution-policy.test.ts server/src/__tests__/issue-monitor-scheduler.test.ts server/src/__tests__/recovery-classifiers.test.ts ui/src/components/IssueMonitorActivityCard.test.tsx ui/src/components/IssueProperties.test.tsx ui/src/lib/activity-format.test.ts` - First run passed 5 files and failed to collect 2 server suites because the worktree was missing the optional `acpx/runtime` dependency. - After `pnpm install --frozen-lockfile`, reran the 2 failed suites successfully. - `pnpm exec vitest run server/src/__tests__/issue-monitor-scheduler.test.ts server/src/__tests__/recovery-classifiers.test.ts` - `pnpm --filter @paperclipai/shared typecheck && pnpm --filter @paperclipai/db typecheck && pnpm --filter @paperclipai/server typecheck && pnpm --filter @paperclipai/ui typecheck` - `pnpm exec vitest run server/src/__tests__/issue-execution-policy.test.ts ui/src/components/IssueProperties.test.tsx` - `pnpm --filter @paperclipai/server typecheck && pnpm --filter @paperclipai/ui typecheck` - `pnpm exec vitest run ui/src/components/IssueMonitorActivityCard.test.tsx ui/src/components/IssueProperties.test.tsx` - `pnpm --filter @paperclipai/ui typecheck` - Storybook screenshot captured from `http://127.0.0.1:6006/iframe.html?viewMode=story&id=product-issue-monitor-surfaces--monitor-surfaces` with Playwright. ## Screenshots 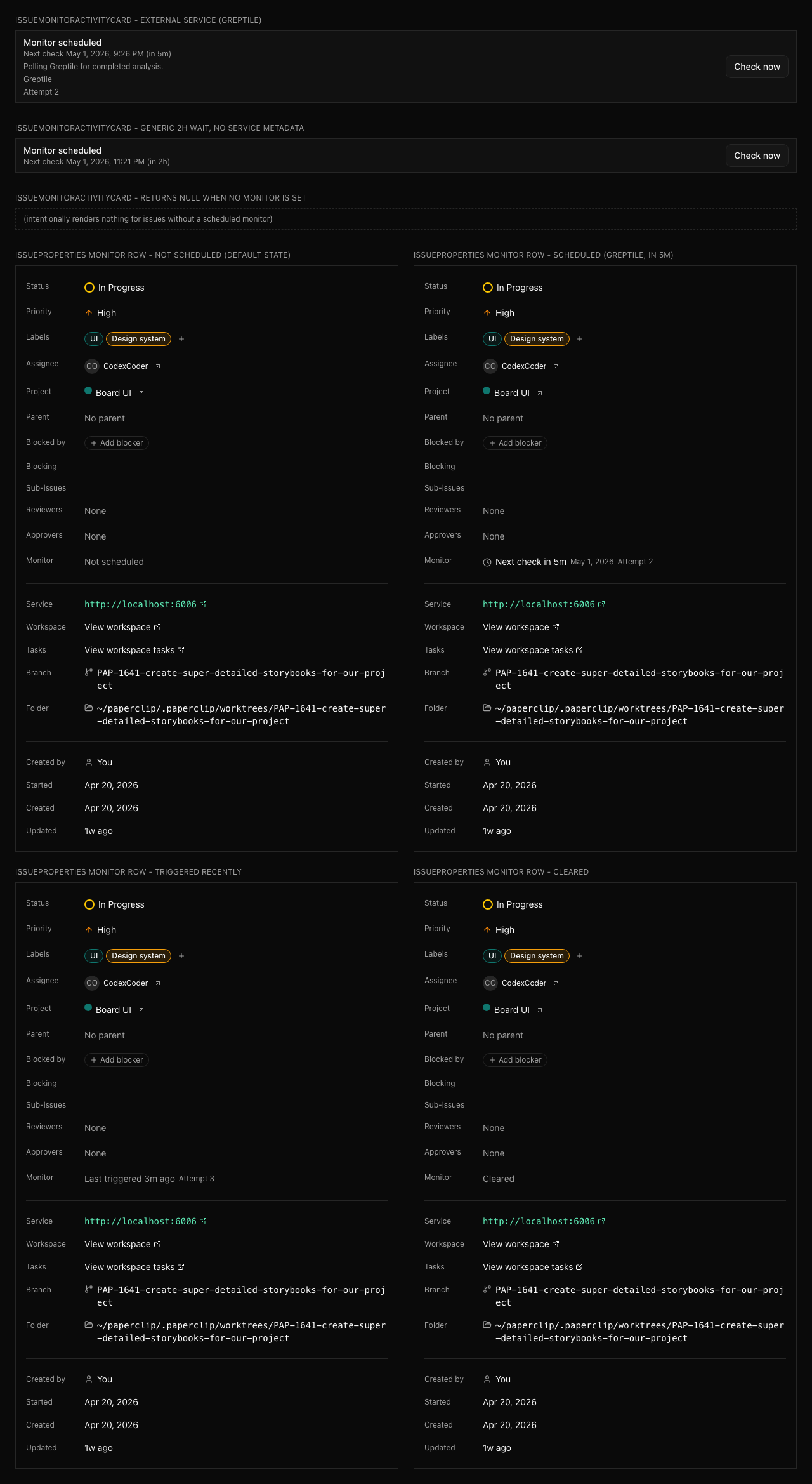 ## Risks - Medium: this changes heartbeat recovery behavior for scheduled external-service waits, so regressions could affect wake timing or recovery issue creation. - Migration risk is reduced by using `IF NOT EXISTS` for the new issue monitor columns and index. - External monitor references are treated as secret-adjacent and are intentionally omitted from visible activity/wake payloads. > For core feature work, check [`ROADMAP.md`](ROADMAP.md) first and discuss it in `#dev` before opening the PR. Feature PRs that overlap with planned core work may need to be redirected — check the roadmap first. See `CONTRIBUTING.md`. ## Model Used - OpenAI Codex, GPT-5 coding agent with repository tool use and terminal execution. ## Checklist - [x] I have included a thinking path that traces from project context to this change - [x] I have specified the model used (with version and capability details) - [x] I have checked ROADMAP.md and confirmed this PR does not duplicate planned core work - [x] I have run tests locally and they pass - [x] I have added or updated tests where applicable - [x] If this change affects the UI, I have included before/after screenshots or Storybook review surfaces - [x] I have updated relevant documentation to reflect my changes - [x] I have considered and documented any risks above - [x] I will address all Greptile and reviewer comments before requesting merge --------- Co-authored-by: Paperclip <noreply@paperclip.ing>
{kind=link}
18 KiB
Execution Semantics
Status: Current implementation guide Date: 2026-04-26 Audience: Product and engineering
This document explains how Paperclip interprets issue assignment, issue status, execution runs, wakeups, parent/sub-issue structure, and blocker relationships.
doc/SPEC-implementation.md remains the V1 contract. This document is the detailed execution model behind that contract.
1. Core Model
Paperclip separates four concepts that are easy to blur together:
- structure: parent/sub-issue relationships
- dependency: blocker relationships
- ownership: who is responsible for the issue now
- execution: whether the control plane currently has a live path to move the issue forward
The system works best when those are kept separate.
2. Assignee Semantics
An issue has at most one assignee.
assigneeAgentIdmeans the issue is owned by an agentassigneeUserIdmeans the issue is owned by a human board user- both cannot be set at the same time
This is a hard invariant. Paperclip is single-assignee by design.
3. Status Semantics
Paperclip issue statuses are not just UI labels. They imply different expectations about ownership and execution.
backlog
The issue is not ready for active work.
- no execution expectation
- no pickup expectation
- safe resting state for future work
todo
The issue is actionable but not actively claimed.
- it may be assigned or unassigned
- no checkout/execution lock is required yet
- for agent-assigned work, Paperclip may still need a wake path to ensure the assignee actually sees it
in_progress
The issue is actively owned work.
- requires an assignee
- for agent-owned issues, this is a strict execution-backed state
- for user-owned issues, this is a human ownership state and is not backed by heartbeat execution
For agent-owned issues, in_progress should not be allowed to become a silent dead state.
blocked
The issue cannot proceed until something external changes.
This is the right state for:
- waiting on another issue
- waiting on a human decision
- waiting on an external dependency or system when Paperclip does not own a scheduled re-check
- work that automatic recovery could not safely continue
in_review
Execution work is paused because the next move belongs to a reviewer or approver, not the current executor.
An external review service can also be a valid review path when the issue keeps an agent assignee and has an active one-shot monitor that will wake that assignee to check the service later.
done
The work is complete and terminal.
cancelled
The work will not continue and is terminal.
4. Agent-Owned vs User-Owned Execution
The execution model differs depending on assignee type.
Agent-owned issues
Agent-owned issues are part of the control plane's execution loop.
- Paperclip can wake the assignee
- Paperclip can track runs linked to the issue
- Paperclip can recover some lost execution state after crashes/restarts
User-owned issues
User-owned issues are not executed by the heartbeat scheduler.
- Paperclip can track the ownership and status
- Paperclip cannot rely on heartbeat/run semantics to keep them moving
- stranded-work reconciliation does not apply to them
This is why in_progress can be strict for agents without forcing the same runtime rules onto human-held work.
5. Checkout and Active Execution
Checkout is the bridge from issue ownership to active agent execution.
- checkout is required to move an issue into agent-owned
in_progress checkoutRunIdrepresents issue-ownership lock for the current agent runexecutionRunIdrepresents the currently active execution path for the issue
These are related but not identical:
checkoutRunIdanswers who currently owns execution rights for the issueexecutionRunIdanswers which run is actually live right now
Paperclip already clears stale execution locks and can adopt some stale checkout locks when the original run is gone.
6. Parent/Sub-Issue vs Blockers
Paperclip uses two different relationships for different jobs.
Parent/Sub-Issue (parentId)
This is structural.
Use it for:
- work breakdown
- rollup context
- explaining why a child issue exists
- waking the parent assignee when all direct children become terminal
Do not treat parentId as execution dependency by itself.
Blockers (blockedByIssueIds)
This is dependency semantics.
Use it for:
- "this issue cannot continue until that issue changes state"
- explicit waiting relationships
- automatic wakeups when all blockers resolve
Blocked issues should stay idle while blockers remain unresolved. Paperclip should not create a queued heartbeat run for that issue until the final blocker is done and the issue_blockers_resolved wake can start real work.
If a parent is truly waiting on a child, model that with blockers. Do not rely on the parent/child relationship alone.
7. Non-Terminal Issue Liveness Contract
For agent-owned, non-terminal issues, Paperclip should never leave work in a state where nobody is responsible for the next move and nothing will wake or surface it.
This is a visibility contract, not an auto-completion contract. If Paperclip cannot safely infer the next action, it should surface the ambiguity with a blocked state, a visible comment, or an explicit recovery issue. It must not silently mark work done from prose comments or guess that a dependency is complete.
An issue is healthy when the product can answer "what moves this forward next?" without requiring a human to reconstruct intent from the whole thread. An issue is stalled when it is non-terminal but has no live execution path, no explicit waiting path, and no recovery path.
The valid action-path primitives are:
- an active run linked to the issue
- a queued wake or continuation that can be delivered to the responsible agent
- a typed execution-policy participant, such as
executionState.currentParticipant - a pending issue-thread interaction or linked approval that is waiting for a specific responder
- a one-shot issue monitor (
executionPolicy.monitor.nextCheckAt) that will wake the assignee for a future check - a human owner via
assigneeUserId - a first-class blocker chain whose unresolved leaf issues are themselves healthy
- an open explicit recovery issue that names the owner and action needed to restore liveness
Agent-assigned todo
This is dispatch state: ready to start, not yet actively claimed.
A healthy dispatch state means at least one of these is true:
- the issue already has a queued wake path
- the issue is intentionally resting in
todoafter a completed agent heartbeat, with no interrupted dispatch evidence - the issue has been explicitly surfaced as stranded through a visible blocked/recovery path
An assigned todo issue is stalled when dispatch was interrupted, no wake remains queued or running, and no recovery path has been opened.
Agent-assigned in_progress
This is active-work state.
A healthy active-work state means at least one of these is true:
- there is an active run for the issue
- there is already a queued continuation wake
- there is an active one-shot monitor that will wake the assignee for a future check
- there is an open explicit recovery issue for the lost execution path
An agent-owned in_progress issue is stalled when it has no active run, no queued continuation, and no explicit recovery surface. A still-running but silent process is not automatically stalled; it is handled by the active-run watchdog contract.
in_review
This is review/approval state: execution is paused because the next move belongs to a reviewer, approver, board user, or recovery owner.
A healthy in_review issue has at least one valid action path:
- a typed execution-policy participant who can approve or request changes
- a pending issue-thread interaction or linked approval waiting for a named responder
- a human owner via
assigneeUserId - an active run or queued wake that is expected to process the review state
- an active one-shot monitor for an external service or async review loop that the assignee owns
- an open explicit recovery issue for an ambiguous review handoff
Agent-assigned in_review with no typed participant is only healthy when one of the other paths exists. Assignment to the same agent that produced the handoff is not, by itself, a review path.
An in_review issue is stalled when it has no typed participant, no pending interaction or approval, no user owner, no active monitor, no active run, no queued wake, and no explicit recovery issue. Paperclip should surface that state as recovery work rather than silently completing the issue or leaving blocker chains parked indefinitely.
Issue monitors
An issue monitor is a one-shot deferred action path for agent-owned issues in in_progress or in_review.
Use a monitor when the current assignee owns a future check against an async system or external service. Examples include Greptile review loops, GitHub checks, Vercel deployments, or provider jobs where the agent should come back later and decide what happens next.
Monitor policy lives under executionPolicy.monitor and includes:
nextCheckAt: when Paperclip should wake the assigneenotes: non-secret instructions for what the assignee should checkserviceName: optional non-secret external-service contextexternalRef: optional external-service reference input; Paperclip treats it as secret-adjacent, redacts it before persistence/visibility, and omits it from activity and wake payloadstimeoutAt,maxAttempts, andrecoveryPolicy: optional recovery hints for bounded waits
Monitors are not recurring intervals. When a monitor fires, Paperclip clears the scheduled monitor and queues an issue_monitor_due wake for the assignee. If the external service is still pending, the assignee must explicitly re-arm the monitor with a new nextCheckAt. If the issue moves to done, cancelled, an invalid status, or a human/unassigned owner, the monitor is cleared.
Because serviceName and notes remain visible in issue activity and wake context, operators should keep them short and non-secret. Put enough context for the assignee to know what to inspect, but do not include signed URLs, bearer tokens, customer secrets, tenant-private identifiers, or provider links with embedded credentials.
Monitor bounds are enforced. Paperclip rejects attempts to re-arm a monitor whose timeoutAt or maxAttempts is already exhausted. When a scheduled monitor reaches an exhausted bound at trigger time, Paperclip clears it and follows recoveryPolicy: wake_owner queues a bounded recovery wake for the assignee, create_recovery_issue opens visible recovery work, and escalate_to_board records a board-visible escalation comment/activity.
Use blocked instead of a monitor when no Paperclip assignee owns a responsible polling path. In that case, name the external owner/action or create first-class recovery/blocker work.
blocked
This is explicit waiting state.
A healthy blocked issue has an explicit waiting path:
- first-class blockers exist, and each unresolved leaf has a valid action path under this contract
- the issue is blocked on an explicit recovery issue that itself has a live or waiting path
- the issue is waiting on a pending interaction, linked approval, human owner, or clearly named external owner/action
A blocker chain is covered only when its unresolved leaf is live or explicitly waiting. An intermediate blocked issue does not make the chain healthy by itself.
A blocked issue is stalled when the unresolved blocker leaf has no active run, queued wake, typed participant, pending interaction or approval, user owner, external owner/action, or recovery issue. In that case the parent should show the first stalled leaf instead of presenting the dependency as calmly covered.
8. Crash and Restart Recovery
Paperclip now treats crash/restart recovery as a stranded-assigned-work problem, not just a stranded-run problem.
There are two distinct failure modes.
8.1 Stranded assigned todo
Example:
- issue is assigned to an agent
- status is
todo - the original wake/run died during or after dispatch
- after restart there is no queued wake and nothing picks the issue back up
Recovery rule:
- if the latest issue-linked run failed/timed out/cancelled and no live execution path remains, Paperclip queues one automatic assignment recovery wake
- if that recovery wake also finishes and the issue is still stranded, Paperclip moves the issue to
blockedand posts a visible comment
This is a dispatch recovery, not a continuation recovery.
8.2 Stranded assigned in_progress
Example:
- issue is assigned to an agent
- status is
in_progress - the live run disappeared
- after restart there is no active run and no queued continuation
Recovery rule:
- Paperclip queues one automatic continuation wake
- if that continuation wake also finishes and the issue is still stranded, Paperclip moves the issue to
blockedand posts a visible comment
This is an active-work continuity recovery.
9. Startup and Periodic Reconciliation
Startup recovery and periodic recovery are different from normal wakeup delivery.
On startup and on the periodic recovery loop, Paperclip now does four things in sequence:
- reap orphaned
runningruns - resume persisted
queuedruns - reconcile stranded assigned work
- scan silent active runs and create or update explicit watchdog review issues
The stranded-work pass closes the gap where issue state survives a crash but the wake/run path does not. The silent-run scan covers the separate case where a live process exists but has stopped producing observable output.
10. Silent Active-Run Watchdog
An active run can still be unhealthy even when its process is running. Paperclip treats prolonged output silence as a watchdog signal, not as proof that the run is failed.
The recovery service owns this contract:
- classify active-run output silence as
ok,suspicious,critical,snoozed, ornot_applicable - collect bounded evidence from run logs, recent run events, child issues, and blockers
- preserve redaction and truncation before evidence is written to issue descriptions
- create at most one open
stale_active_run_evaluationissue per run - honor active snooze decisions before creating more review work
- build the
outputSilencesummary shown by live-run and active-run API responses
Suspicious silence creates a medium-priority review issue for the selected recovery owner. Critical silence raises that review issue to high priority and blocks the source issue on the explicit evaluation task without cancelling the active process.
Watchdog decisions are explicit operator/recovery-owner decisions:
snoozerecords an operator-chosen future quiet-until time and suppresses scan-created review work during that windowcontinuerecords that the current evidence is acceptable, does not cancel or mutate the active run, and sets a 30-minute default re-arm window before the watchdog evaluates the still-silent run againdismissed_false_positiverecords why the review was not actionable
Operators should prefer snooze for known time-bounded quiet periods. continue is only a short acknowledgement of the current evidence; if the run remains silent after the re-arm window, the periodic watchdog scan can create or update review work again.
The board can record watchdog decisions. The assigned owner of the watchdog evaluation issue can also record them. Other agents cannot.
11. Auto-Recover vs Explicit Recovery vs Human Escalation
Paperclip uses three different recovery outcomes, depending on how much it can safely infer.
Auto-Recover
Auto-recovery is allowed when ownership is clear and the control plane only lost execution continuity.
Examples:
- requeue one dispatch wake for an assigned
todoissue whose latest run failed, timed out, or was cancelled - requeue one continuation wake for an assigned
in_progressissue whose live execution path disappeared - assign an orphan blocker back to its creator when that blocker is already preventing other work
Auto-recovery preserves the existing owner. It does not choose a replacement agent.
Explicit Recovery Issue
Paperclip creates an explicit recovery issue when the system can identify a problem but cannot safely complete the work itself.
Examples:
- automatic stranded-work retry was already exhausted
- a dependency graph has an invalid/uninvokable owner, unassigned blocker, or invalid review participant
- an active run is silent past the watchdog threshold
The source issue remains visible and blocked on the recovery issue when blocking is necessary for correctness. The recovery owner must restore a live path, resolve the source issue manually, or record the reason it is a false positive.
Instance-level issue-graph liveness auto-recovery is disabled by default. When enabled, its lookback window means "dependency paths updated within the last N hours"; older findings remain advisory and are counted as outside the configured lookback instead of creating recovery issues automatically. This is an operator noise control, not the older staleness delay for determining whether a chain is old enough to surface.
Human Escalation
Human escalation is required when the next safe action depends on board judgment, budget/approval policy, or information unavailable to the control plane.
Examples:
- all candidate recovery owners are paused, terminated, pending approval, or budget-blocked
- the issue is human-owned rather than agent-owned
- the run is intentionally quiet but needs an operator decision before cancellation or continuation
In these cases Paperclip should leave a visible issue/comment trail instead of silently retrying.
12. What This Does Not Mean
These semantics do not change V1 into an auto-reassignment system.
Paperclip still does not:
- automatically reassign work to a different agent
- infer dependency semantics from
parentIdalone - treat human-held work as heartbeat-managed execution
The recovery model is intentionally conservative:
- preserve ownership
- retry once when the control plane lost execution continuity
- create explicit recovery work when the system can identify a bounded recovery owner/action
- escalate visibly when the system cannot safely keep going
13. Practical Interpretation
For a board operator, the intended meaning is:
- agent-owned
in_progressshould mean "this is live work or clearly surfaced as a problem" - agent-owned
todoshould not stay assigned forever after a crash with no remaining wake path - parent/sub-issue explains structure
- blockers explain waiting
That is the execution contract Paperclip should present to operators.